Информационные технологии управления знаниями
4
Для того, чтобы Семантический Веб мог функционировать, компьютеры должны иметь доступ к структурированным хранилищам информации и множествам правил вывода, которые могли бы использоваться для проведения автоматических рассуждений. Однако два хранилища информации или базы данных могут использовать различные идентификаторы для обозначения одного и того же понятия, такого, например, как почтовый индекс. И программа, желающая сравнить или как-то скомбинировать информацию из этих баз данных, должна знать, что два конкретных термина используются ими для обозначения одного и того же. В идеале, у программы должен быть способ распознавать подобные термины с одинаковым смыслом, с какими бы базами данных ей не пришлось столкнуться в процессе своей работы.
Решение этой проблемы даётся третим базовым компонентом Семантического Веба — совокупностью информации, которое специалисты именуют онтологией (см. статью про инженерию знаний). В философии онтологией называют некую теорию о природе бытия, ИТ-специалисты заимствовали этот термин, и для них уже онтология — это структура, задающая отношения между понятиями.
Онтология определяет классы объектов и отношения между ними. Например, понятие адрес может быть определено как разновидность понятия местонахождение [location], а код города можно задавать применительно лишь к местонахождениям и так далее. Задание классов, подклассов, а также отношений между индивидами [entities] является чрезвычайно мощным инструментом для использования в Вебе.
В простейшем случае, онтологии используют для увеличения точности поиска в Вебе — поисковая машина будет выдавать только такие сайты, где упоминается в точности искомое понятие, а не произвольные страницы, в тексте которых встретилось данное многозначное ключевое слово.
В полную силу Семантический Веб будет реализован тогда, когда люди создадут множество программ - агентов, которые, знакомясь с содержимым Веба из различных источников, обрабатывают полученную информацию и обмениваются результатами с другими программами. Семантический Веб стимулирует подобного рода синергию: даже те агенты, которые не были созданы специально для работы сообща, могут передавать информацию друг другу, коль скоро эта информация будет снабжена семантикой.
Полноценный Семантический Веб – это технология управления знаниями будущего, однако, уже сейчас можно пользоваться его отдельными технологиями и применять в ограниченных областях. Примером является Семантический веб организации — или реализация этой концепции в рамках отдельной организации [Cerebra, 2005].
Также и онтологии могут не только использоваться в Семантическом Вебе, но и применяться в системах управления знаниями предприятий. Онтологии задают единый язык, повышая тем самым эффективность коммуникаций сотрудников и обмен знаниями. Они могут использоваться для интеграции информации и выполнения простых автоматических рассуждений, повышая тем самым качество результатов поиска информации. Современные исследователи [Mika, Akkermans, 2004; Davies et al, 2005] считают онтологии основной парадигмой управлением знаниями предприятия.
Сегодняшние поисковые системы зачастую выдают бесчисленное множество совершенно не относящихся к запросу «хитов», обрекая пользователя на длительный ручной отбор материала. Например, если вы ввели для поиска слово «орган», то компьютеру совершенно непонятно, имеете ли вы в виду музыкальный инструмент, часть человеческого тела или орган исполнительной власти. Вся проблема в том, что для компьютера слово «орган» не имеет чёткого смысла, или другими словами, семантического содержания.
Онтологии дают возможность производить запросы на основе понятий, а не на основе совпадения строк. Например, если пользователь задаст вопрос «Какие транспортные средства производятся в России?», то он получит из базы ответ, в который попадут автомобили (=подкласс транспортных средств) производимые во Всеволожске (=город, который находится в России).
Также онтологии дают возможность получения не заданных явно знаний из информационных хранилищ путем логического вывода - поиск «скрытой информации». Например, пользователь системы может задать вопрос: Какие поставки продукции находятся сейчас в состоянии риска? В ответ на такой вопрос система в одной онтологии тарифов определит, что с учетом текущих условий (например, географических или погодных) существуют риски связанные с перевозкой овощей и фруктов. А в другой базе или онтологии деклараций по перевозке груза определит, что в декларации №А345 указаны арбузы, которые являются подклассом «Овощей и фруктов» (см. рис. 3). В результате, система сможет дать кокретный ответ на поставленный вопрос: Поставка COSCO #A345
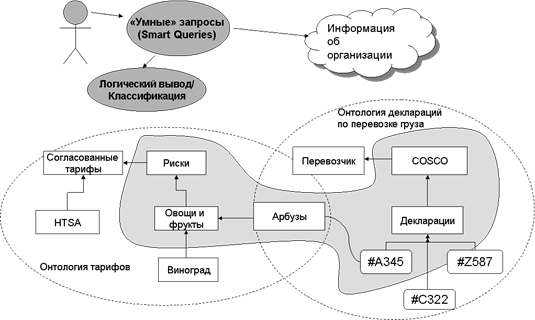
Рис. 3 Интеллектуальный поиск на основе логического вывода
6. Архитектура СУЗ и ее реализация
Для описания типичной современной архитектуры СУЗ мы несколько адаптировали рисунок из работы [Mika, Akkermans, 2004].
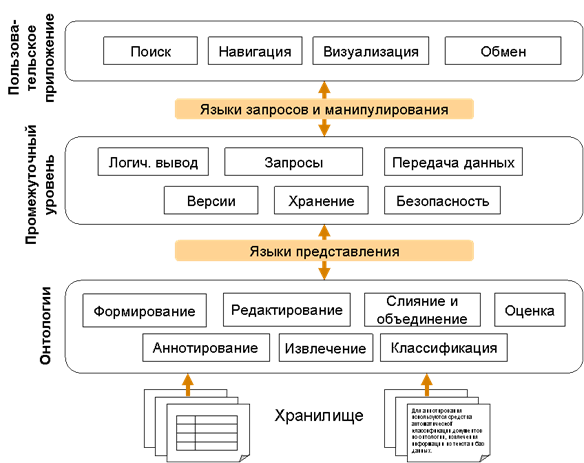
Рис. 4. Пример архитектуры СУЗ
Нижний уровень архитектуры (Рис.4) обеспечивает получение знаний из разнородных источников структурированной (базы данных и знаний, таблицы, формы) и неструктурированной (документы) информации. Получение знаний подразумевает аннотирование разнородных источников информации с помощью онтологии, которая позволяет отразить содержание информации. Для получения онтологии используются программные средства автоматического формирования онтологии, поддержки ручной разработки и редактирования онтологии, средства слияния, объединения и оценки качества онтологий. Для аннотирования используются средства автоматической классификации документов по онтологии, извлечения информации из текста и баз данных. Полученные онтологии и метаданные представляются с помощью специальных языков – OWL, RDF.
Промежуточный уровень обеспечивает хранение онтологий и метаданных, управление версиями, доступом, передачу данных для взаимодействия с внешними системами и хранилищами, обработку запросов и логический вывод.
Пользовательские приложения предоставляют пользователям доступ к знаниям, находящимся в системе. Доступ может осуществляться с помощью поискового механизма, средств навигации и визуализации, а также путем непосредственного обмена знаниями между пользователями (например, путем обмена ссылками на ресурсы). Взаимодействие пользовательских приложений с промежуточным уровнем осуществляется с помощью языков запросов и манипулирования данными (например, SPARQL).
Представленная на рис. 4 архитектура может воплощаться в СУЗ полностью или частично. В одних случаях упор может делаться на программную реализацию задач уровня пользовательских приложений – поиск, визуализацию знаний, в других на получение, хранение, интеграцию знаний. В первом случае программная реализация скорее всего будет носить имя «портала знаний», во втором «корпоративной памяти» или «базы знаний».
А) Корпоративная память
Одним из первых инструментов УЗ стали хранилища данных, которые работают по принципу центрального склада. Как правило, хранилища содержат многолетние версии обычной базы данных (БД), физически размещаемые в той же самой базе. Когда все данные содержатся в едином хранилище, изучение и анализ связей между отдельными элементами могут быть наиболее эффективны. В дальнейшем идея хранилища была развита в понятие корпоративной памяти (corporate memory) [Kühn, Abecker, 1998], которая по аналогии с человеческой памятью позволяет накапливать информацию из предыдущего опыта и якобы избегать повторения ошибок, что является чисто декларативным утверждением.